Der Weg zu den essentiellen Leuchten-Daten – Datenanalyse zu einem KompAKI Use Case
In den verschiedensten Anwendungsfällen wird KI heutzutage schon im operativen Betrieb verwendet. Bevor man jedoch mit einer Implementierung eines KI-Algorithmus beginnen kann, müssen entsprechend repräsentative Daten in ausreichenden Mengen vorhanden sein. In Bezug auf Deep Learning, wird eine sehr große Datenmenge benötigt [1]. Aber neben der Quantität zählt auch die Qualität der Daten, denn nur aus repräsentativen Datensätzen lässt sich ein KI-Algorithmus mittels überwachtem Lernen (supervised learning) effektiv trainieren [2]. Daher ist neben dem Sammeln von Daten auch eine ausgiebige Datenanalyse und -aufbereitung notwendig.
Die Datenanalyse für den KI Use Case der Firma TRILUX GmbH & Co. KG, über den bereits in einem vorangegangenen Blog-Beitrag berichtet wurde, erfolgte in einem iterativen Prozess zwischen den Partnern der h_da und TRILUX.
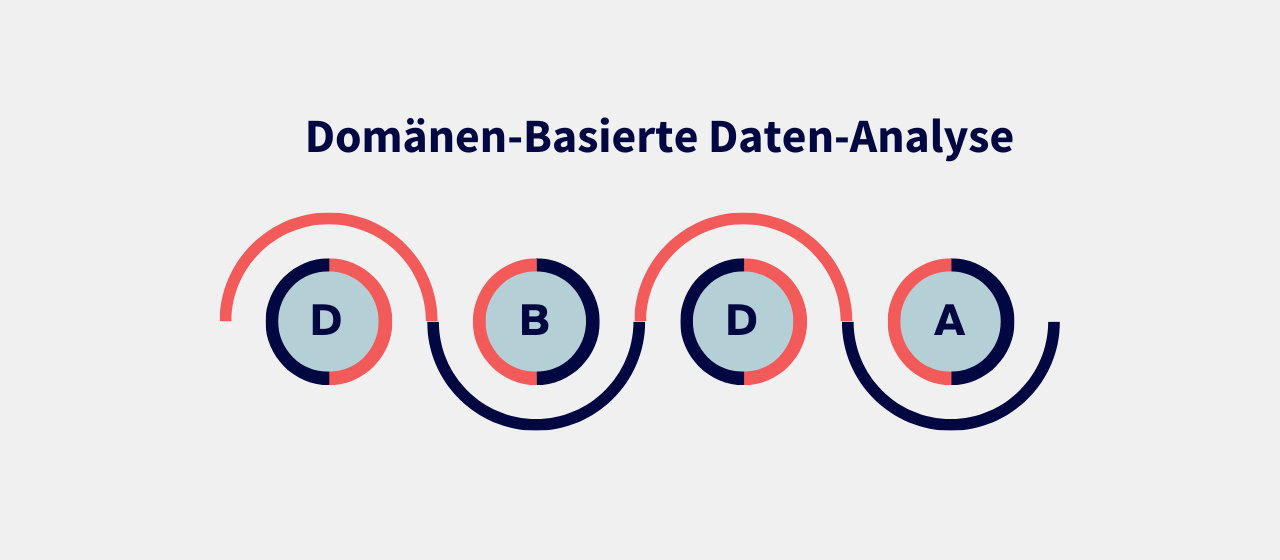
Der erste Schritt bestand darin, zu verstehen, was einen Prüfplan umfasst und wie man eine zweifelsfreie Zuordnung zu den Auftragsdaten gewährleisten kann. Dazu wurden in regelmäßigen Workshops Mitarbeitende der Qualitätssicherung befragt, um auf Basis ihres Wissens ein prinzipielles Vorgehen für eine spezifische Datenanalyse erarbeitet. Das Konzept wurde als Domänen-basierte Daten-Analyse (DBDA) bereits in einem weiteren Blog-Beitrag von KompAKI vorgestellt.
Parallel dazu beschäftigte sich ein studentisches Seminarprojekt mit den vorhandenen Datenbanken, sowie den darin enthaltenen Parametern. Jede zu fertigende Leuchte erhält einen einzigartigen Eintrag in den Datenbanken und jeder Eintrag besteht aus einer Vielzahl verschiedener Parameter. Als Basis für die Datenanalyse diente eine Vorarbeit der Firma TRILUX, welche sich bereits mit Auswahlkriterien zur Prüfplanerstellung auseinandersetzte. So konnten schließlich mehrere Dutzend Parameter ausgemacht werden, welche die Auswahl eines passenden Prüfplans beeinflussen. Von diesen Kriterien ist bereits ein überwiegender Teil in den Datenbanken vorhanden [3].
Das Team einigte sich für das weitere Vorgehen auf eine spezifische Leuchten-Reihe geeinigt, dessen Auswahlkriterien auf den ersten Blick bereits in den Datenbanken vorzuliegen schienen.
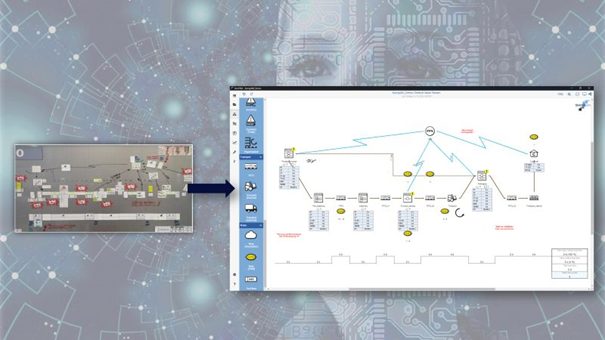
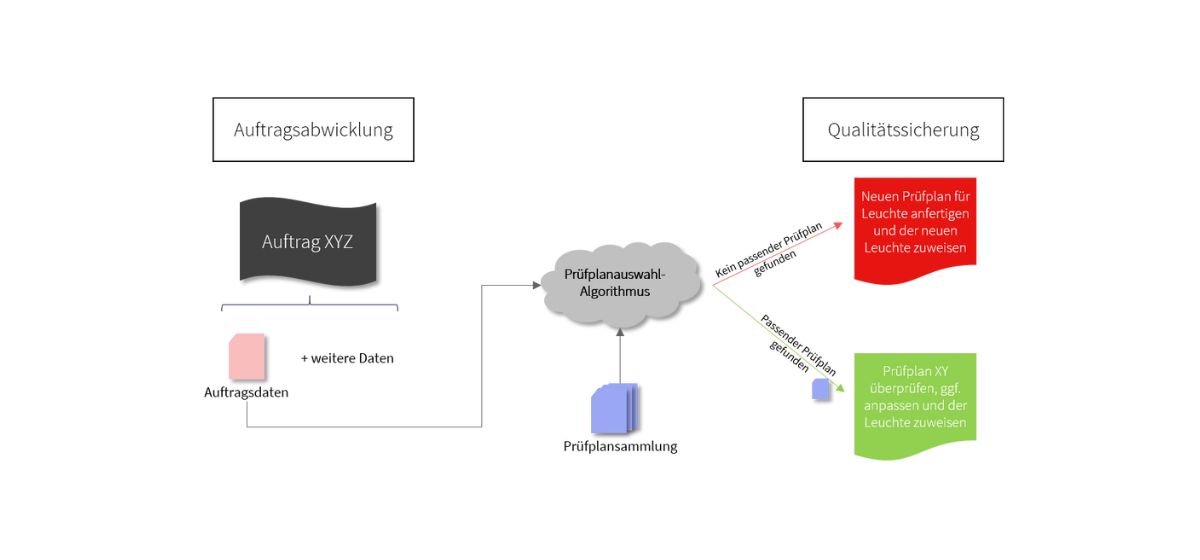
Für eben diese Leuchten-Reihe folgte in einem darauffolgenden Schritt eine tiefgründige Datenanalyse, welche im Rahmen einer Praktikumsarbeit durchgeführt wurde [4]. Dazu wurden die Einträge aus den Datenbanken in Bezug auf Wertebereiche, Vollständigkeit, sowie Relevanz genauer untersucht und eine manuelle Zuordnung zu den richtigen Prüfplänen vorgenommen. Bei einigen zuvor kritischen Parametern mussten leider fehlende Werte in den Datenbanken festgestellt werden, sodass alternative Kriterien in Betracht gezogen werden mussten. Nach intensiver Arbeit konnte schließlich ein einfaches Referenzmodell entworfen werden, welches eine Leuchte aus der Leuchten-Reihe mittels Datenbank-Parametern eindeutig dem richtigen Prüfplan zuweisen kann. Ein beispielhafter Auszug für die gewählte Leuchten-Reihe ist in Abbildung 1 zu sehen.

Abbildung 1: Beispielhafte Zuordnung einer Leuchten-Reihe über Datenbank-Parameter
Die Datenanalyse verlief nach dem Prinzip „Reduzieren, Zusammenfassen und Vergleichen“ und beläuft sich auf die folgenden Schritte:
- Datensatz reduzieren: Alle Parameter, welche unklassifizierbar oder informationsarm sind (z.B. wenn ein Parameter hat alle Einträge keinen oder immer nur denselben Inhalt hat) können bereits aus dem Datensatz entfernt werden.
Beispiel für den Use Case: Einige Parameter besaßen in allen Einträgen denselben Inhalt, sind daher informationsarm und wurden von der weiteren Analyse ausgeschlossen. Dazu gehört bspw. die Spannungsversorgung der Leuchte, da diese für die gesamte Leuchten-Reihe auf 230V ausgelegt ist.
- Einträge zu Gruppen zusammenfassen: In diesem Schritt sollen alle Einträge der Datenbank in Gruppen zusammengefasst werden, welche sich jeweils in dem Wert eines bestimmten Parameters unterscheiden. Dieser Parameter sollte für den spezifischen Use Case relevant sein.
Beispiel für den Use Case: Hier wurde bspw. die Schutzklasse(SK) einer Leuchte gewählt, mir der die Einträge der Datenbank in eine Gruppe „Schutzklasse I“ und eine Gruppe „Schutzklasse II“ aufgeteilt werden konnten.
- Gruppen vergleichen: Schließlich betrachtet man die restlichen Parameter aller Datenbank-Einträge innerhalb der Gruppen und stellt diese gegenüber. Dabei sollten zunächst alle Parameter gestrichen werden, welche in allen Datenbank-Einträgen einen identischen Wert besitzen.
Beispiel für den Use Case: Innerhalb der beiden Gruppen zur Schutzklasse der Leuchte hatten einige Parameter keine Wertveränderung sind also erneut informationsarm, weswegen diese aus der Analyse gestrichen wurden.
- Relevanz der Parameter prüfen: Je nach Use Case haben bestimmte Parameter zur Zielfindung keine Relevanz und können ebenfalls vernachlässigt werden.
Beispiel für den Use Case: Das Datum des erhaltenen Auftrags ist als Parameter zur Prüfplanauswahl nicht relevant, da sich die Prüfroutine in dem gegebenen Zeitraum auf keine andere Prüfnorm anpassen musste. Deswegen wurde dieser Parameter aus der Analyse gestrichen.
- Parameter bewerten: Dieser Schritt beschäftigt sich final mit der Frage, ob der gewählte Parameter geeignet ist oder ausreicht, um einen Zusammenhang zwischen Einträgen und gesuchtem Zielwert festzustellen.
Beispiel für den Use Case: Als Zielwert ist in diesem Use Case der Prüfplan gemeint. Die Unterscheidung zwischen den beiden Schutzklassen führte zu einer eindeutigen Zuordnung der Prüfpläne in jeweils eine Gruppe. Deswegen ist der Parameter zur Bewertung prinzipiell geeignet. Jedoch ist noch keine eindeutige Zuordnung zu einem einzelnen Prüfplan möglich, weswegen die Schutzklasse der Leuchte alleine nicht dafür ausreicht.
Die Schritte 2-5 müssen ggf. wiederholt werden, wenn der Zielwert noch nicht eindeutig festgestellt werden konnte.
Beispiel für Use Case: Da noch keine eindeutige Zuordnung zu einem bestimmten Prüfplan möglich war, wurde nach weiteren Gruppen gesucht (bspw. Lichtsystem).
Nach einigen Iterationen der Datenanalyse war diese für den Anwendungsfall von TRILUX abgeschlossen. Im Folgenden werden nun geeignete Algorithmen ausgewählt, ein erster Prototyp implementiert und schließlich evaluiert.
[1]: Y. Roh, G. Heo and S. E. Whang, „A Survey on Data Collection for Machine Learning: A Big Data – AI Integration Perspective,“ in IEEE Transactions on Knowledge and Data Engineering, vol. 33, no. 4, pp. 1328-1347, 1 April 2021, doi: 10.1109/TKDE.2019.2946162
[2]: Braun, S., & Follwarczny, D. (2021). KI-Projekte–diese Rolle spielt die Datenqualität
[3]: Auszug aus Resultaten des Seminarprojekts mit Herrn Berg und Herrn Strack, in Kooperation zwischen h_da und TRILUX GmbH & Co. KG, durchgeführt zwischen April – Juli 2021
[4]: Auszug aus Resultaten des Praktikums von Herrn Storck, in Kooperation zwischen h_da und TRILUX GmbH & Co. KG, durchgeführt zwischen Oktober 2021 – Januar 2022